




“機(jī)器學(xué)習(xí)的目的不只是為了搜索,而是信息,Google 會保持這方面的領(lǐng)導(dǎo)力。”Google 創(chuàng)始人艾瑞克·施密特(Eric Schmidt)在 Google 的亞太媒體會議上這么說。
為了展示這個“領(lǐng)導(dǎo)力”,Google 周二開源了一個名為 TensorFlow的機(jī)器學(xué)習(xí)系統(tǒng),把自家積累的大數(shù)據(jù)開放給所有人。也就是說,來自移動設(shè)備和大型計(jì)算機(jī)的開發(fā)者都能使用 Google 積累了數(shù)年的數(shù)據(jù),來構(gòu)建自家的人工智能應(yīng)用。
九成收入來自廣告的 Google(Alphabet)想讓人工智能成為下一個重要的影響力和收入來源,Google 為此在東京舉辦了一場媒體峰會,邀請來自亞太地區(qū)的 90 多家媒體來告訴大家 Google 在這方面實(shí)力強(qiáng)大。
不過,和機(jī)器學(xué)習(xí)有關(guān)的 TensorFlow 能做什么?
先來看看機(jī)器學(xué)習(xí)是怎么一回事
“機(jī)器學(xué)習(xí)不是魔法,它是一種工具。”Google Brain 項(xiàng)目的發(fā)起者 Greg Corrado 在這場會議上說。

Greg Corrado
作為人工智能的分支領(lǐng)域,機(jī)器學(xué)習(xí)的概念大致是:一臺計(jì)算機(jī)能像人類一樣,從無數(shù)的數(shù)據(jù)當(dāng)中獲得“經(jīng)驗(yàn)”,從而有判斷和預(yù)測的能力。
Corrado 說,要想讓機(jī)器判斷準(zhǔn)確,需要人類喂食大量的數(shù)據(jù),Google 認(rèn)為這正是他們的優(yōu)勢所在。施密特說,Google 從七八年前就開始了數(shù)據(jù)積累。
Google Brain 在 2011 年立項(xiàng),這個“大腦”現(xiàn)如今已經(jīng)有 10-30 層的“神經(jīng)網(wǎng)絡(luò)”,并在 2012 年分析了 1000 萬隨機(jī)圖片,學(xué)習(xí)了“貓”是怎么一回事,然后自動找出了另外 2 萬張圖片里所有的貓。
圖像識別,這是 TensorFlow 能做的第一件事
類似識別“貓”的功能,已經(jīng)在 Google Photos 上實(shí)現(xiàn)了。這個今年 5 月分推出的應(yīng)用,除了有“無限、免費(fèi)”的云端存儲容量,還能自動的幫你把照片歸類。
在東京的會議上,Google Photos 的產(chǎn)品經(jīng)理 Chirs Perry 掏出自己的手機(jī),搜索人名、地名、甚至“斗牛犬”這樣看似苛刻的關(guān)鍵字,這個應(yīng)用都能“認(rèn)識”并且把結(jié)果展示出來。
類似的圖像識別就是 TensorFlow 的第一個應(yīng)用,它的開源意味著,今后其他開發(fā)者也能開發(fā)類似 Google Photos 的程序。
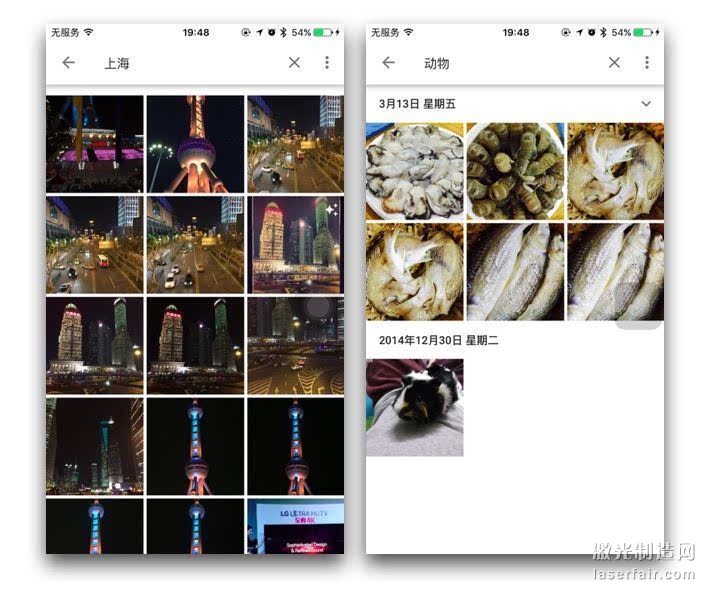
Google Photos
機(jī)器學(xué)習(xí)能讓郵箱更智能
Google 在機(jī)器學(xué)習(xí)的其他應(yīng)用還有郵件。除了 Gmail 能自動識別垃圾郵件,Inbox 也剛剛上線了一個新功能:自動回復(fù)郵件。根據(jù)每封郵件的具體內(nèi)容,它能顯示三個回復(fù)的短句供你選擇。
當(dāng)然這一切的前提是 Google 能獲知你的所有數(shù)據(jù),而且數(shù)據(jù)越多,Google 對你郵件的判斷就越準(zhǔn)確和個性化。
而關(guān)于隱私問題的爭議,Google 倒是對自家的安全措施很自信,Corrado 說,他們有強(qiáng)大的安全加密技術(shù),施密特更是表示“你們想讓數(shù)據(jù)安全,就把數(shù)據(jù)放到 Google 來吧!”
語義識別也需要數(shù)據(jù),比如翻譯應(yīng)用
除了圖片和郵件,Google 也把機(jī)器學(xué)習(xí)應(yīng)用到語義識別上。在東京媒體會議的現(xiàn)場,Google 專門開辟一個展示空間,讓媒體體驗(yàn) Google Translate 能干什么。
如果你把手機(jī)的攝像頭對準(zhǔn)某行外文,Google Translate 能在屏幕上實(shí)時顯示翻譯后的語言,像是上圖這樣。
不過這個神奇的功能只支持少數(shù)語言,更多的語言能在拍照模式下得到翻譯——你不必一個字一個字輸入。
Corado 表示,機(jī)器翻譯并不需要具體的規(guī)則,它是一個不斷自我糾正的過程。數(shù)據(jù)庫越大,翻譯的結(jié)果就越準(zhǔn)確。

Google Translate
那么,Google 為什么要把自己的數(shù)據(jù)庫開源?
實(shí)際上,TensorFlow 作為一個機(jī)器學(xué)習(xí)系統(tǒng),在 Google 內(nèi)部已經(jīng)被使用了一段時間,開源意味著 Google 能獲得更多的數(shù)據(jù)來源。
“研究者和開發(fā)者能給我們更好的反饋,我們會有更大的進(jìn)步,整個行業(yè)會變得更智能。”施密特這么解釋開源的原因。在這個“進(jìn)步”的過程中,Google 自然也能獲得更多行業(yè)的主動權(quán),也能發(fā)現(xiàn)更多人才。
因?yàn)槎⒅斯ぶ悄艿牟恢?Google 一家,蘋果、微軟、Facebook、百度等都在招兵買馬。比如微軟小冰的營銷文案中,這個語音助理被定義為“一個 17 歲的萌妹子”。
最后,我們真的可以把人工智能比作大腦嗎?
今天大小科技公司都在談人工智能,而神經(jīng)網(wǎng)絡(luò)計(jì)算則是說明自己技術(shù)前沿的最佳例證。當(dāng)它的原理被市場部們幾經(jīng)簡化之后,已經(jīng)變成“像人腦神經(jīng)網(wǎng)絡(luò)一樣工作”。
實(shí)際上,二者僅僅有極其微弱和模糊的聯(lián)系。
“我們的確不知道大腦是怎么運(yùn)作的,它不是形容計(jì)算機(jī)一個合適的模型,這個比喻被過度解讀了。二者的相似性僅僅是神經(jīng)元的連接方式,實(shí)際上他們的的學(xué)習(xí)方式是完全不同的。”Corado 告訴記者。
施密特也說:“我們不認(rèn)為讓計(jì)算機(jī)模仿大腦可以去做人工智能,我覺得這個太復(fù)雜,大腦的神經(jīng)元太多了,計(jì)算機(jī)只是借助了人類大腦的一些概念。”
畢竟,我們連自己的大腦到底是怎么工作都還不知道呢。
轉(zhuǎn)載請注明出處。

 相關(guān)文章
相關(guān)文章
 熱門資訊
熱門資訊
 精彩導(dǎo)讀
精彩導(dǎo)讀






























 關(guān)注我們
關(guān)注我們

